CSV
CSV는 Comma Separate Value의 약자로, 필드를 쉼표(,)로 구분한 텍스트 파일이다
wget -Uri https://bit.ly/3psoUZb -OutFile .\ai_math\lec3\customer.csvwget을 통해 파일을 다운받아준다. 나는 윈도우를 쓰고 있기 때문에 다음과 같이 작성해주었다.
""" code """
cust_lst = []
data_header = []
line_counter = 0
f = open("./data/customer.csv", "r")
while 1:
data = f.readline().rstrip() #끝 공백 제거하고 한 줄씩 읽어오기
if not data: break #데이터가 없다면, 즉, 끝나면 종료
if line_counter == 0: #첫 번째 줄은 필드명
data_header = data.split(",") #필드 모두 저장
else :
cust_lst.append(data.split(","))
line_counter += 1
f.close()
print("필드명 : ", data_header)
print("데이터", *cust_lst[:5], sep="\n")""" 결과 """
필드명 : ['customerNumber', 'customerName', 'contactLastName', 'contactFirstName', 'phone', 'addressLine1', 'addressLine2', 'city', 'state', 'postalCode', 'country', 'salesRepEmployeeNumber', 'creditLimit']
데이터
['103', '"Atelier graphique"', 'Schmitt', '"Carine "', '40.32.2555', '"54', ' rue Royale"', 'NULL', 'Nantes', 'NULL', '44000', 'France', '1370', '21000']
['112', '"Signal Gift Stores"', 'King', 'Jean', '7025551838', '"8489 Strong St."', 'NULL', '"Las Vegas"', 'NV', '83030', 'USA', '1166', '71800']
['114', '"Australian Collectors', ' Co."', 'Ferguson', 'Peter', '"03 9520 4555"', '"636 St Kilda Road"', '"Level 3"', 'Melbourne', 'Victoria', '3004', 'Australia', '1611', '117300']
['119', '"La Rochelle Gifts"', 'Labrune', '"Janine "', '40.67.8555', '"67', ' rue des Cinquante Otages"', 'NULL', 'Nantes', 'NULL', '44000', 'France', '1370', '118200']
['121', '"Baane Mini Imports"', 'Bergulfsen', '"Jonas "', '"07-98 9555"', '"Erling Skakkes gate 78"', 'NULL', 'Stavern', 'NULL', '4110', 'Norway', '1504', '81700']
Web
HTML 형태로 데이터를 보내는데, HTML은 웹 상의 정보를 구조적으로 표현하기 위한 언어이며 태그를 사용하여 구조를 표시한다
정규식
파이썬에선 re 모듈을 import해서 사용한다
search : 한 개만 찾기
findall : 전체 찾기
위와 같은 함수를 통해 찾은 패턴은 튜플로 반환된다
import re
import urllib.request
url = "https://bit.ly/3rxQFS4"
html = urllib.request.urlopen(url)
html_contents = str(html.read())
id_results = re.findall(r"([A-Za-z0-9]+\*\*\*)", html_contents)
for result in id_results:
print(result)
결과>>
codo***
outb7***
dubba4***
multicuspi***
crownm***
triformo***
spania***
magazin***
.
.
.
NUMPY
넘파이를 사용하는 가상환경을 새로 만들어주자.
$ conda create -n upstage python=3.8
$ conda activate upstage
$ conda install numpybase에서 upstage로 가상환경을 바꿔주고, 넘파이를 설치해주었다.
ndarray
넘파이의 배열이다. 아래와 같이 생성해준다.
데이터 타입을 정해주면서 생성한다는 점에서 기존 리스트와는 조금 다르다.
arr = mp.array(배열, 데이터타입)
=> arr = np.array([1,2,3], float)
Reshape
reshape이란 array의 shape 크기를 변경해준다.
reshape(m,n) : m행 n열로 모양변화를 준다.
'-1'로 나머지를 통해 알아서 계산 가능함
flatten
다차원 배열을 1차원 배열로 펴주는 역할
Slicing
넘파이 슬라이싱은 기존 리스트 슬라이싱과는 조금 다르다.
[a:b]란? a 이상 b 미만
arr = np.array([[0,1,2,3],[0,4,5,6],[0,7,8,9]],int)
print(arr[:2 , 1:4])
결과>>
[[1 2 3]
[4 5 6]]
axis
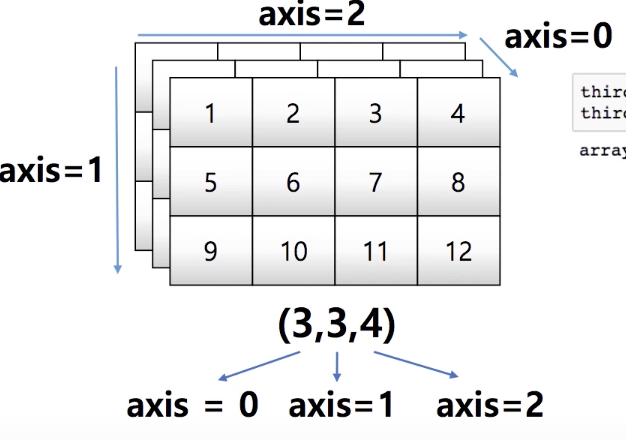
새롭게 생성되는 축이 axis = 0이 된다.
concatenate
넘파이 배열 합치는 함수
vstack : 행과 행의 합산
hstack : 열과 열의 합산
all & any
all : 모두가 조건에 만족해야 True
any : 하나라도 만족하면 True
'부스트캠프 > day 정리' 카테고리의 다른 글
| [week 1 - day 4] 딥러닝 ~ 베이즈 통계학 (0) | 2023.03.10 |
|---|---|
| [week 1 - day 3] 경사하강법 (0) | 2023.03.09 |
| [week1 - day 3] 벡터 & 행렬 (0) | 2023.03.08 |
| [week 1 - day 2] Pandas (0) | 2023.03.08 |
| [week 1 - day 2] Exception Handling (0) | 2023.03.07 |