Abstract
최근 연구에서 입출력 사이에 shorter connections을 포함시키면, Convolution Network이 깊어지고 정확해지며 학습 효율도 높아진다고 밝혀졌다. 이 논문은 이러한 관찰을 기반으로 Dense Convolutional Network(DenseNet)을 제시한다.
기존의 연구(AlexNet, VGG, GoogLeNet 등의 일반적인 CNN)구조에선 각 레이어 간에 한 개의 연결만 존재하다.(L->L) 그렇기 때문에 많은 필터를 거치면서 소실 문제가 생기는 것이다.
이러한 문제를 완화하기 위해, 본 논문은 네트워크 내의 모든 층이 서로 직접적으로 연결되는 밀집 연결(dense connectivity) 구조를 제안한다. 이 구조는 단순한 연결 구조보다 학습 효율성을 학습시켜 고도의 정확도를 달성할 수 있다.
Related Work
선행 연구들에 대해 조금 더 살펴봅시다.
기존 LeNet5는 5개의 레이어, VGG19는 19레이어처럼 갈수록 깊은 네트워크를 생성할 수 있었습니다. 하지만, 이렇게 cnn이 점점 깊어짐에 따라 새로운 문제가 발생하는데, 입력 정보나 기울기가 많은 레이어를 통과하면서 사라지는 문제가 생기는 것입니다. 그래서 많은 모델이 매우 깊은 네트워크를 생성할 수 없었지만,
이 논문이 발행되기 전, ResNet이 나오면서 이를 해결합니다.
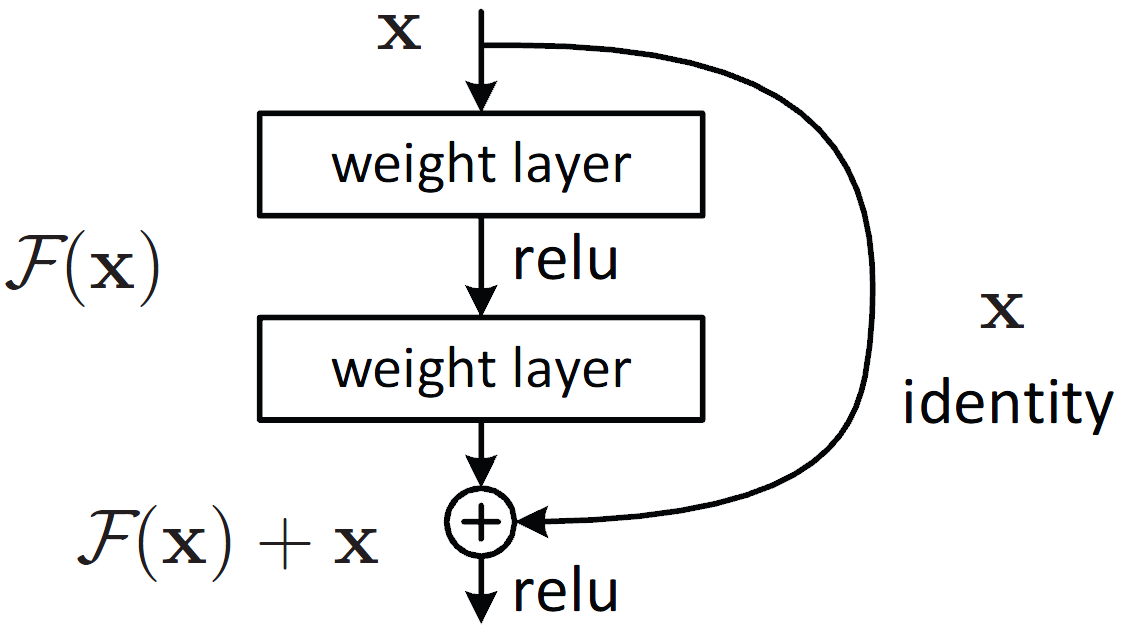
ResNet을 다루는 것이 아니다보니 간단하게 설명하고 넘어가자면, Residual block은 위 그림과 같이 두 개의 경로를 포함합니다. x 입력을 그대로 출력에 전달하여 입력값을 보존하며 소실 문제를 해결할 수 있고, F(x)를 통해 잔여학습 효과도 내는 것입니다. (과제에서 이를 1 by 1 컨볼루션으로 구현했었는데, 이처럼 1 by 1 컨볼루션을 통해 차원을 맞춰주고 더해주면서 깊고 안정적인 학습을 진행하는 것입니다.)
또한, 이 논문에서 이전 연구로 FractalNets 모델 또한 언급을 했는데, 저는 처음 들어서 한 번 찾아봤습니다.
이 또한, ResNet처럼 깊은 네트워크를 갖고 있는데, 다양한 깊이를 갖는 네트워크를 결합하여 깊이를 늘리는 방식을 사용합니다.

위와 같은 구조로 구성되어 있는데, 보시다시피 다양한 크기의 블록이 사용되어 더 다양한 네트워크 구조를 구성한다고 합니다. 또한, 이 다양한 크기의 블록이 또 다른 컨볼루션 레이어를 가져서 네트워크 전체의 깊이가 불규칙하게 된다고 합니다. 그래서, ResNet처럼 residual block이 아니여도 깊은 네트워크를 쌓을 수 있습니다.
이제 진짜 본론으로 와서, 이 논문에서 그럼 무엇을 제안하는가?에 대해 말씀드리려고 합니다.
이 논문에선 ResNet, FractalNets에서 사용된 개념을 이용해 새로운 방식의 네트워크를 제시합니다.
마찬가지로 short connection을 사용하지만, 이전 모든 레이어의 출력을 현재 레이어의 입력으로 사용합니다. 이를 통해 병목현상과 그레디언트 소실 문제를 해결할 수 있습니다.
아까 ResNet을 설명하면서, ResNet이 병목현상과 그레디언트 소실 문제를 해결한다고 했습니다. 여기서 DenseNet만이 장점에 대해 설명드리자면, 네트워크의 매개변수 수를 줄일 수 있습니다. 아까 L개의 레이어로 (L-1)*L/2의 효과를 내기 때문에 더 적은 파라미터로 많은 효과를 낼 수 있는 것 입니다.
또한, ResNet은 병목현상을 어느정도 해결했다고 해도, 경로가 복잡하고 깊어질수록 병목현상이 생길 수 있습니다. 그러나 ,DenseNet은 밀집한 연결 구조를 사용해, 이전 레이어의 출력을 모두 입력으로 받아들이기 때문에 병목현상이 크게 발생하지 않습니다.
🤔질문 : 병목 현상이 뭔가요?
👀답변 : 네트워크 내에서 특정 레이어나 노드에서 정보가 쌓여 제대로 흐르지 못해 학습 성능이 저하되는 것 입니다 !
🤔질문 : 그렇다면 DenseNet이 왜 병목 현상을 줄일 수 있는거죠?
👀답변 : 각 레이어에서 이전 레이어의 모든 출력값을 사용하기 때문에, 특정 레이어에서 병목이 발생할 가능성이 줄어들어 조금 더 안정적으로 학습이 가능합니다 !
또한 장점 하나를 더 말씀 드리자면, 조밀한 연결이 정규화 효과를 가져와 오버피팅을 줄이는 것도 가능하다고 합니다 !
🤔질문 : 조밀한 연결이 왜 정규화 효과를 가져올 수 있는거죠?
👀답변 : 이전 모든 레이어의 출력이 현재 레이어의 입력에 사용되면서, 전체 네트워크 정보에 직접적으로 접근 가능하게 됩니다. 어떤 레이어에서든 이전 모든 레이어의 특징을 사용할 수 있어 노이즈가 줄어들며, 이는 일종의 정규화 효과를 가져옵니다 !
본 논문에선 DenseNet에 대해 4가지 장점에 대해 소개하는데, 구조를 이해하면서 왜 이러한 장점이 생겼는지 생각해봅시다 !
1. vanishing gradient problem (경사 소실 문제) 완화
2. feature propagation 강화 (특징 전파 강화)
3. 특징 재사용 촉진 (특징 재사용 유도)
4. 매개 변수의 수를 줄인다. (파라미터 수 감소)
DenseNet
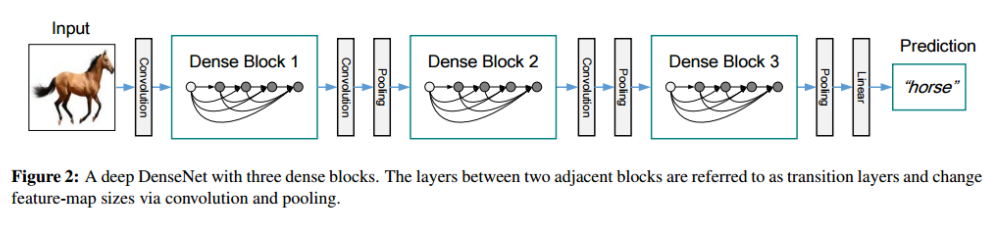
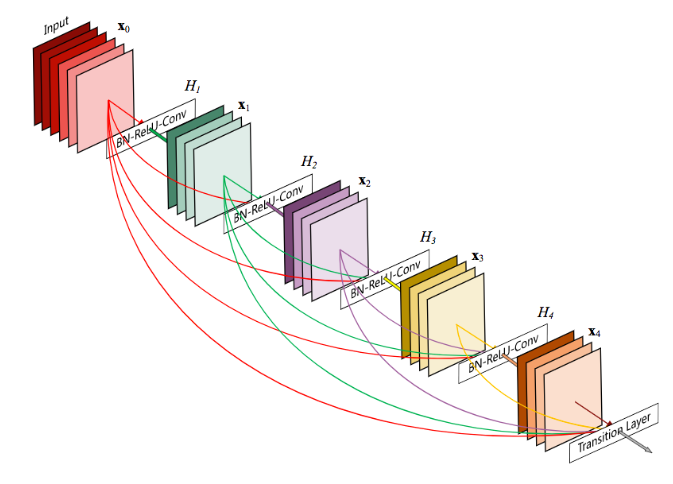
위는 DenseNet의 전체적인 구조입니다. 컨볼루션과 풀링을 반복하다가 마지막에 FC레이어가 있다는 것은 매우 익숙하실겁니다! 다른 모델과 비슷하니깐요. 하지만, DenseNet는 다른 모델과 달리 Dense Block을 가집니다.
composite function

Dense Block이 뭘까요? 이를 뜯어보면 사실 익숙할 것입니다.
Composite function은 Dense Block 내에서 사용되는 함수로 이는 BatchNorm->ReLU->Conv 순서로 이루어져 있습니다. Batch Norm을 통해 입력 데이터를 정규화하여 안정화시키고, ReLU라는 비선형성을 추가하여 딥러닝 모델의 복잡성을 증가시키고, 컨볼루션을 통해 특징을 추출하는 역할을 합니다.
Growth rate
논문에서 각 Dense Block의 layer가 이전 layer들의 feature-map에 접근할 수 있다는 특징을 이용해, 전체적인 지식을 활용할 수 있다고 언급합니다. Growth rate는 새로운 레이어에 추가되는 feature maps의 수를 제어하는 hyper_parameter입니다.
예를 들어, 각 layer에서 k개의 feature map이 생성되면, i번째의 레이어는 이전 레이어들의 feature_map에 K0 + k * (i-1)개의 채널을 가지고 들어가게 되는 것 !
아래 그림을 보면 확실히 이해될 것 입니다.
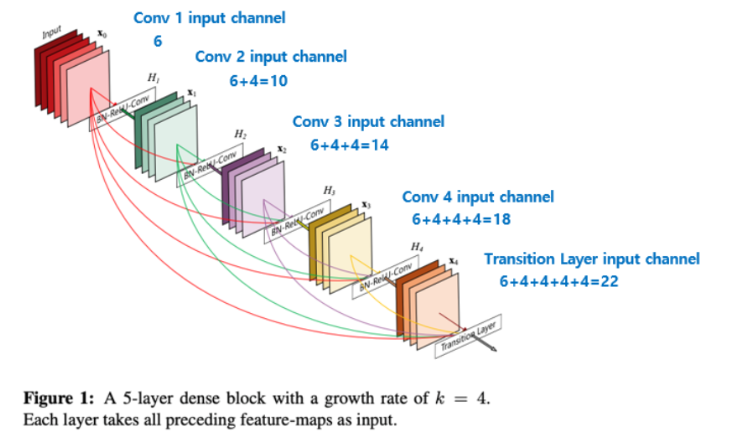
논문에서 각 Dense Block의 layer가 이전 layer들의 feature-map에 접근할 수 있다는 특징을 이용해, 전체적인 지식을 활용할 수 있다고 언급했습니다. Growth rate는 새로운 레이어에 추가되는 feature maps의 수를 제어하는 hyper_parameter이다. growth rate가 4일 때, 6에서 4를 더해 10이 되고, 10에서 4를 더해 14가 되고,
이런 식으로 4씩 더해지는 것입니다.
Bottleneck Layer
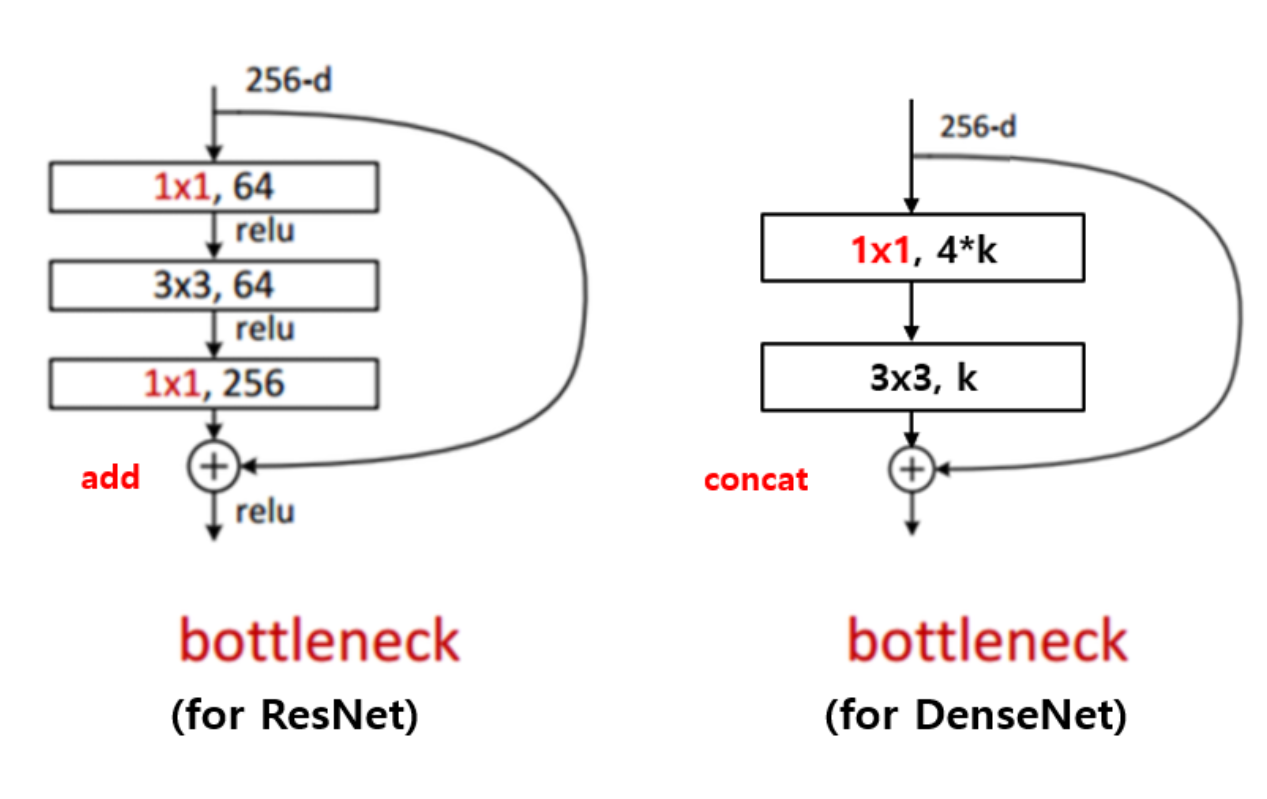
DenseNet에서 각 레이어는 k개의 작은 아웃풋을 생성하지만, 이는 일반적으로 많은 인풋 Feature map을 가지고 있습니다. 이는 모델이 깊어진다는 장점이 있지만, 이로 인해 인풋의 크기가 증가하는 문제가 발생할 수 있습니다.
그래서 ResNet과 비슷하게 bottlenect layer를 추가합니다. 이 때, DenseNet는 ResNet과 다르게 concat 형태로 추가해주는 것을 볼 수 있습니다.
🤔질문 : 차이는 알겠지만, 그게 무슨 효과가 있나요 ?
👀답변 : 덧셈 연산을 사용하려면 차원이 같아야 합니다. 즉, ResNet은 shortcut connection을 사용해 identity mapping이 가능해지지만, DenseNet은 그럴 필요가 없습니다. 위 사진에서 보시면, 마지막에 더해주기 전에 1 by 1 컨볼루션으로 다시 차원을 맞춰줍니다. DenseNet은 그런 연산이 필요하지 않습니다 !
즉, ResNet은 매 레이어마다 입력과 출력 크기가 같아야한다는 제약이 있지만 DenseNet은 없다는 것 !
또한, 위에서 말한 장점이 여기에 존재합니다.
우선 소실 문제를 해결할 수 있습니다. concat 형태로 값을 보존하며 붙이는 것이기 때문에 ResNet도 피하지 못한 소실 문제를 해결할 수 있는 것입니다.
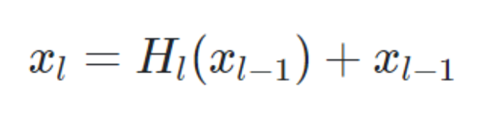
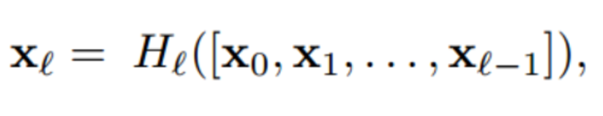
위 식을 보실까요?
ResNet는 이전 레이어 값을 보존합니다. 그렇기 때문에 기존 CNN보다 소실 문제를 피할 수 있었습니다. 하지만, 층이 깊어질수록 초반의 레이어가 유지될 수 있을까요? L이 커질수록 0,1,...번째 레이어들은 소실될 수 있습니다.
하지만, DenseNet은 0,1,..부터 l-1까지 모두 concat하여 현재 레이어(l번째)에 전달합니다. 소실 문제를 여기서 해결하는 겁니다.
또 다른 장점이 있습니다.
식을 보면 알 수 있듯이, x0번째부터 파라미터를 공유합니다. 파라미터의 수를 줄일 수 있을 뿐만 아니라 네트워크의 전체적인 흐름에 접근할 수 있는 것이죠. (사실, 모든 장점이 연결되어 있습니다. 이는 또 피쳐 재사용을 유도하고, 이는 또 피쳐 프로파게이션을 강화하니깐요 !)
앞서 개념을 통해 어느정도 흐름을 파악했을 겁니다. 이제 논문을 간단하게 구현해보겠습니다 !
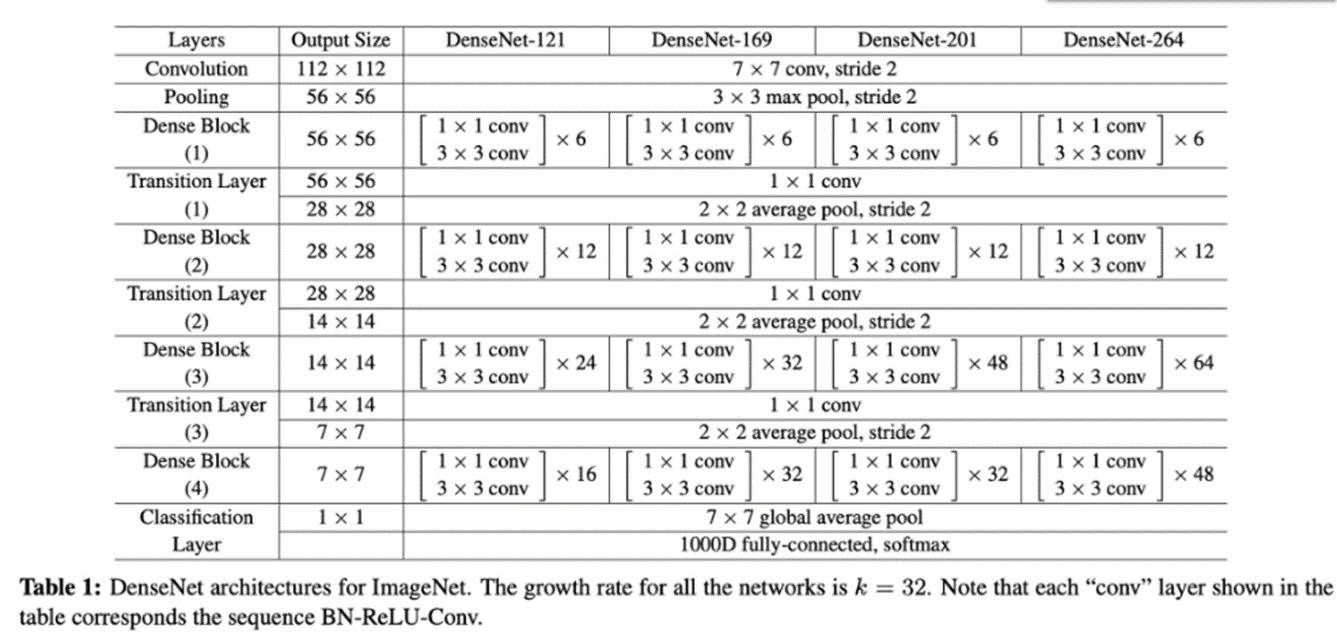
저는 여기서 DenseNet-121을 구현해보려고 합니다.
보시면 Dense Block은 1by1 컨볼루션 이후 3by3 컨볼루션이 진행되는 것을 알 수 있고,
Transition Layer도 1by1 컨볼루션 이후 7by7 average pool이 진행되는 것을 알 수 있습니다.
한 코드에 여러 번 반복하면 코드가 길고 복잡해지기 때문에, 아래와 같이 따로 선언해주었습니다.
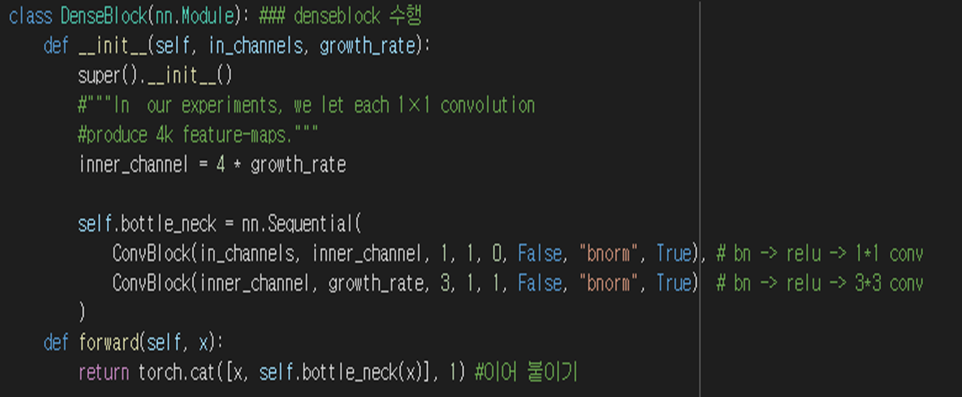
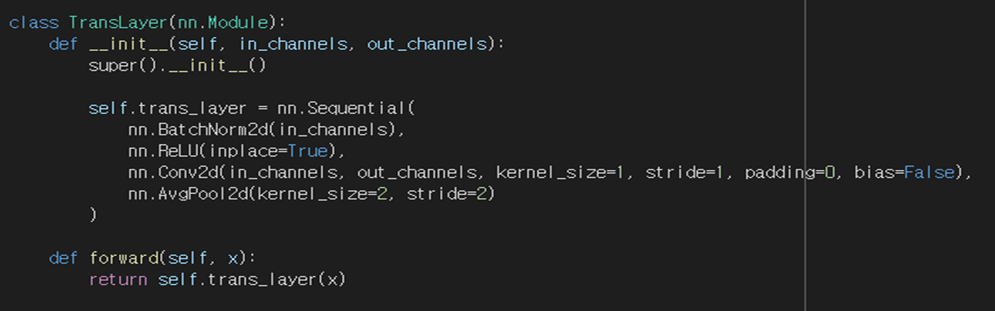

전체 코드는 아래와 같습니다.

코드가 정리가 안 돼서 이쁘지 않습니다.. 그냥 흐름정도만 봐주시면 좋을 듯 합니다.
아래는 모델 검증 코드입니다.

데이터셋에 5개의 label이 존재했는데, 구현모델의 레이어를 거쳐 5개로 된 것을 확인할 수 있었습니다.
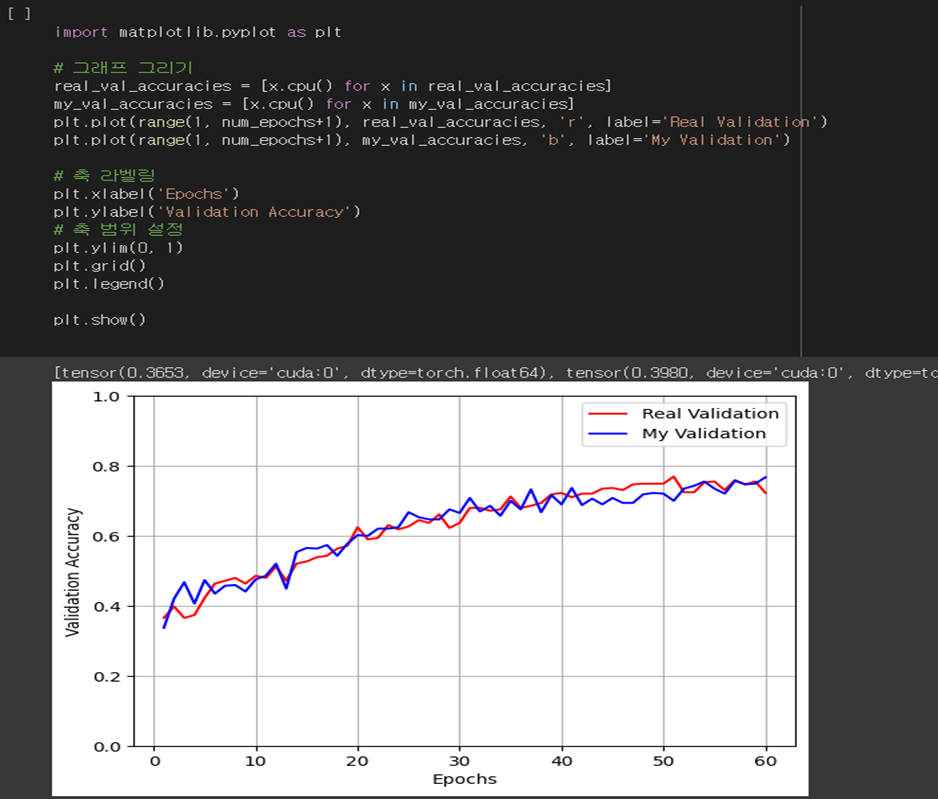
학습 이후 그래프로 그래봤습니다.
파란 색이 제가 구현한 DenseNet121이고, 빨간 색은 실제 DenseNet121입니다. 정확도가 크게 차이나진 않지만, 대체적으로 성능이 낮은데 이는 제가 매우 작은 데이터셋을 돌려서 그렇습니다😥
한 label당 500개도 안되는 데이터셋이었습니다 다음엔 큰 데이터셋으로 돌려볼 계획입니다.
자세한 코드는 아래 깃에 존재합니다 !
https://github.com/DaHyeonnn/paper.git
제가 이해한대로 적고 코드를 구현한거라 틀린 개념 지적 매우 환영합니다
'논문리뷰' 카테고리의 다른 글
| hidden technical debt in machine learning systems 논문 공부 (0) | 2023.09.05 |
|---|---|
| Scene Text Detection and Recognition (0) | 2023.05.26 |