성능 데이터 모델링
DB 성능 향상을 위한 사항이 데이터 모델링에 반영되도록 하는 것
사전에 할수록 저렴하지만, 분석/설계 단계에서 수행할 경우 재업무 비용을 감소시킬 수 있음.
고려 사항 : 정규화, DB 용량, 트랜잭션 유형 파악
- 모델링 순서
1) 정규화를 정확하게 수행한다
2) 데이터베이스 용량을 산정한다.
3) 트랜잭션 유형 파악
4) 용량과 트랜잭션에 따라 반정규화를 수행
5) 조정 (pk, 슈퍼타입, 서브타입 조정)
6) 성능 관점에서 데이터 모델 검증
정규화와 성능
- 정규화란 ?
데이터 분해 과정으로 이상현상(anomaly)를 제거하는 것이다.
- 함수적 종속성
결정자와 종속자의 관계로, 결정자의 값으로 종속자의 값을 알 수 있음
결정자 ► 종속자
ex ) 주민등록번호 ► (이름,출생지,주소)
기본적으로 데이터는 속성간의 함수종속성에 근거하여 정규화되어야 한다.
- 1차 정규화란 ?
속성의 원자성을 확보하려는 것. 다중값 속성을 분리한다.
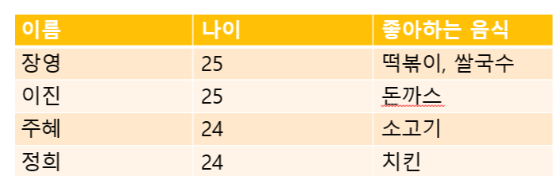
다음과 같이 장영이 좋아하는 음식이 2가지이므로 컬럼이 원자값을 가지지 않아 1차 정규형을 만족하지 못하고 있다.
그렇기에 1차 정규화를 진행해 분해하여 칼럼이 하나의 원자값을 가지도록 한다.
2차 정규화란 ?
부분 함수 종속성을 제거하는 것이다.
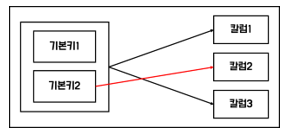
다음과 같이 복합키의 부분집합이 결정자가 되었을 때, 이를 분리해주어야 하는 것이다. 이것이 2차 정규화 !
3차 정규화란 ?
제 2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다.
이행적 종속이라는 것은 A -> B, B -> C가 성립할 때, A->C가 성립되는 것을 의미한다.
즉, 기본키 이외에 다른 컬럼이 그 외의 다른 컬럼을 결정할 수 없다는 것이다.
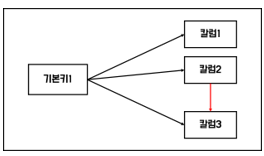
- 정규화 장점
위와 같은 정규화를 통해,
1) 데이터 양을 줄여 성능 향상
2) 유연성 증가
3) 개념을 세분화하여 재활용 가능성 증가
4) 데이터 중복 최소화
와 같은 효과를 생성한다.
BUT, 정규화로 인해 성능 저하가 발생할 수 있다.
조회 시 처리 조건에 따라 성능 저하가 발생할 수 있음. CPU와 메모리를 많이 사용하게 됨
해결 방안 => 반정규화, 인덱스 사용
| 조회성능 | 처리조건에 따라 성능이 향상될 수 있음 |
| 처리조건에 따라 성능이 저하될 수 있음 | |
| 입력/수정/삭제 성능 | 성능이 향상됨 |
반정규화란 ?
데이터 중복을 허용하여 조인을 줄이는 DB 성능 향상 방법.
데이터 무결성이 깨지는 것을 감수해서라도 반정규화를 실시해 조회 성능을 향상시킨다.
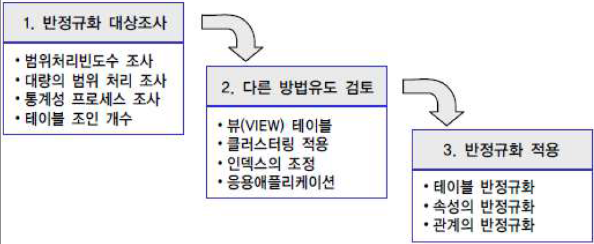
- 반정규화 절차
1. 반정규화 대상 조사 (데이터 처리 범위 및 통계성 등 조사)
2. 다른 방법을 검토해본다 (EX. 뷰, 클러스터링, 인덱스, 애플리케이션)
3. 반정규화 적용 : 정규화 수행 후 반정규화를 수행한다.
- 테이블 반정규화란 ?
테이블 병합/분할/추가를 실시한다.
| 테이블 반정규화 |
테이블 병합 | 1:1 관계 테이블 병합 | 분리된 테이블의 join연산으로 성능이 저하되었던 것을 병합하여 성능을 높인다. |
| 1:M 관계 테이블 병합 | |||
| 슈퍼-서브타입 테이블 병합 | |||
| 테이블 분할 | 수직분할 | 트랜잭션 처리 유형 파악이 선행되어야 한다. 자주 사용하는 특정 칼럼들로 분할한다. 디스크 I/O를 분산처리하기 위함이다. ex. (일자, 사번, 방법, 코드, 번호) -> (일자, 방법), (사번, 코드, 번호) |
|
| 수평분할 | 자주 사용하는 특정 튜플들로 분할한다. ex. 데이터들을 월별로 분리 -> 수납이력 1월, 2월, 3월.... |
||
| 테이블 추가 | 중복테이블 추가 | 다른 업무이거나 서버가 다른 경우, 원격조인을 제거하여 성능을 높인다. | |
| 통계테이블 추가 | SUM, AVG등을 미리 계산해 둠으로써 성능을 높인다. | ||
| 이력테이블 추가 | 마스터테이블의 레코드를 중복한다. | ||
| 부분테이블 추가 | 자주 사용하는 특정 칼럼들로 구성된 테이블을 생성한다. 디스크 I/O를 줄이기 위함이다. |
- 칼럼 반정규화란 ?
| 칼럼 반정규화 |
중복칼럼 추가 | 조인을 감소시키기 위해 추가한다. | |
| 파생칼럼 추가 | 미리 계산한 칼럼을 추가한다. | ||
| 이력테이블 칼럼 추가 | 대량의 테이블에서 불특정한 날짜 조회나 최근 값을 조회할 때의 성능저하를 방지하기 위해 기능성칼럼(최근값 여부, 시작과 종료일자 등)을 추가한다 |
||
| PK에 의한 칼럼 추가 | 복합의미를 갖는 PK를 단일 속성을 구성했을 때 발생한다. PK의 값을 중복하여 일반속성으로 추가한다. |
||
| 오작동을 위한 칼럼 추가 | 잘못 처리할 경우 값을 복구하기 위해 이전 데이터를 임시적으로 중복하여 보관한다. | ||
- 관계 반정규화란 ?
데이터의 무결성 보장함
| 관계 반정규화 |
중복관계 추가 | 많은 조인 발생 시 성능저하를 방지하기 위해 추가적인 관계를 맺는다. |
|
대량 데이터에 따른 성능
- 블록 : 테이블의 데이터 저장 단위
- 대량 데이터 발생으로 인한 현상 :
블록 I/O 횟수 증가 → 디스크 I/O 가능성 상승 (디스크 I/O 시 성능 저하)
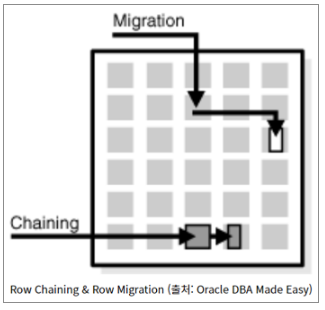
| Row Chaining | Row Migration |
| 행 길이가 너무 길어서 데이터 블록 1개에 모두 저장되지 않고 다음 블록으로 넘어가 저장되는 형태이다. | 저장공간이 부족한 상황에서 10만큼 저장되어있던 데이터를 15만큼으로 변경하고자 하면 다른 블록을 찾아 저장해야하는 형태 |
| 두 기법으로 성능저하가 발생하면, 트랜잭션을 분석하여 적절하게 1:1 관계로 분리하여 성능을 향상한다. | |
pk에 의한 테이블 파티셔닝(Range, List, Hash 파티셔닝)
| Range 파티셔닝 | 데이터가 날짜 또는 숫자로 분리가 가능한 경우에 적용한다. SQL문을 실행할 땐 내부적으로 구분된 테이블에서 처리하여 성능이 개선된다. 데이터 보관주기에 따른 테이블 관리가 용이하다. ex. 년/월을 이용하여 12개의 파티션 테이블을 만든다. |
| List 파티셔닝 | 특정한 값을 기준으로 분할 |
| Hash 파티셔닝 | 지정된 hash조건에 따라 해슁 알고리즘이 적용된다. 설계자도 어떤 테이블에 어떤 데이터가 들어갔는지 알 수 없다. |
슈퍼/서브타입 모델의 성능고려방법
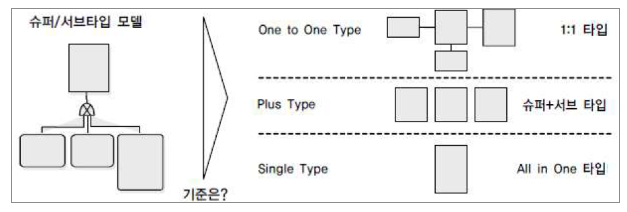
공통부분을 슈퍼타입으로 모델링하고, 내용을 상속받아 서브타입 엔터티를 만들어
업무의 내용을 정화하게 표현한다.
| One to One Type 1:1 타입 |
Plus Type 슈퍼+서브 타입 |
Single Type All in One 타입 |
|
| 설명 | 슈퍼타입과 서브타입 각각 트랜잭션이 발생하면 개별 테이블로 구성하여 1:1 관계를 갖도록 한다. ex. 슈퍼타입에 이름을 넣으면, 서브타입으로 세부정보가 나오는 경우 |
슈퍼타입과 서브타입 함께 트랜잭션이 발생하면 슈퍼타입의 PK와 각 서브타입의 속성을 묶어 N개의 테이블을 구성한다. ex. 슈퍼타입과 서브타입이 1개 테이블로 통합되어있고 A칼럼만 개별적으로 많이 처리하는데 B, C 등의 칼럼내용까지 포함되어있어서 필요없는 처리가 발생하게되는 경우. (PK당사자번호, 이해관계인, 대리인, 매수인) -> (FK당사자번호, 이해관계인) -> (FK당사자번호, 대리인) -> (FK당사자번호, 매수인) |
왼쪽 예제에서 당사자번호, 이해관계인,..의 속성을 항상 통합처리하거나 슈퍼+서브타입을 정확히 지정하지 못하는 상황에서는 하나의 테이블로 구성한다. |
| 확장성 | 좋음 | 보통 | 나쁨 |
| 조인성능 | 나쁨 | 나쁨 | 좋음 |
| I/O량 성능 | 좋음 | 좋음 | 나쁨 |
| 관리용이성 | 나쁨 | 나쁨 | 좋음(1개) |
참고 블로그 :
https://jiyoungtt.tistory.com/47
https://javagirl.tistory.com/47?category=853450
https://lotuus.tistory.com/49
'SQLD' 카테고리의 다른 글
| [SQLD] 2과목-1 오답노트 (0) | 2023.03.06 |
|---|---|
| [SQLD 자격증] 2과목 - 강의 정리(1) (0) | 2023.02.27 |
| [SQLD 자격증] 1과목 2 - 데이터 모델과 성능 오답노트 (0) | 2023.02.14 |
| [SQLD 자격증] 1과목 - 데이터 모델링의 이해의 오답노트 (1) (0) | 2023.02.12 |
| [SQLD 자격증] 1과목 - 데이터 모델링의 이해 (1) (0) | 2023.02.11 |