CNN(Convolutional Neural Network)이란 ?
이미지와 같은 2D 데이터를 처리하기 위한 딥러닝 모델이고, CNN은 Convolutional Layer, Pooling Layer, Fully Connected Layer 등으로 구성되어 있다.
Convolutional Layer에서는 이미지같은 입력 데이터를 필터(kernel)와 합성곱 연산을 통해 다양한 feature를 추출하는 것이다.
합성곱 연산은 입력 데이터와 필터를 일정 간격으로 겹쳐가며 곱하고 더하는 연산이다.
이러한 연산을 통해 출력 데이터 크기를 계산할 수 있다.

공식은 위와 같다.
주의할 점은 입력 데이터의 채널 수와 kernel의 채널 수가 같아야 하는 것 !
parameter 개수 공식 : (kernel 가로*세로*채널 수 + bias) * 출력 채널 수
아래는 개인적인 질문이다. 사실, 옛날에 인공지능 수업을 들었을 땐 열심히 이해하고 넘어갔었는데 다~ 까먹었다~
1. stride가 왜 필요한가?
stride를 늘리면 출력 크기가 감소한다. => 파라미터 수 감소 => 복잡도 줄임 => 과적합 방지 => 효율 good
2. padding이 왜 필요한가?
입력 데이터 사이드에 0을 패딩해주어 입력 데이터 정보를 보존
padding 없이 convolution layer를 쌓다보면, 크기가 감소하면서 정보가 손실될 것 !
AlexNet
2012년 이미지넷(ImageNet) 대회에서 우승한 딥러닝 모델 중 하나이다.
5개의 컨볼루션 레이어와 3개의 fully connected 레이어, 총 8개의 레이어로 구성되어 있다.
AlexNet부터 컨볼루션 레이어를 중심으로 구성하기 시작했다.
ReLU 활성화 함수를 사용하여 모델의 연산 속도, 안정성 향상
Dropout를 통해 overfitting을 방지함
Local Response Normalization(LRN)의 사용 => 성능 높이기
+) 여기서 궁금한 점
1. 그래서 컨볼루션 레이어 사용이 왜 좋은 것인지?
내 생각 : 파라미터를 줄일 수 있다? 이전까지는 fully connected layer를 사용하였는데, 이는 매우 많은 파라미터가 필요하니까 !
정답 : 내 생각과 얼추 비슷한 것 같다. 조금 더 자세히 설명하자면, 필터 크기와 스트라이드를 조절하여 출력 이미지의 크기를 줄일 수 있어 파라미터 개수가 줄어드는 것 !!!!
우선 fully connected layer는 32*32*3(h*w*rgb)의 이미지가 있으면, 그것을 3072*1의 크기로 변환하는 레이어다. 즉, flatten 함수와 같다고 생각하면 된다. 클래스가 10개라면, 파라미터의 개수는 30720개가 된다.
이 때, 컨볼루션 레이어를 사용하는 것 !
컨볼루션 레이어틀 사용해서 입력 이미지의 공간 정보를 보전하면서도 kernel 크기와 stride를 조절하여 출력 이미지 크기를 줄여 파라미터 개수를 줄이는 것이다.
위 32*32*3 경우를 다시 예로 들어, 컨볼루션 레이어를 사용해보자.
3*3 크기의 kernel 32개를 사용하고, stride 1을 적용하자.
그럼 output size는30*30*32가 된다. parameter 개수는 (3*3*3)*32 = 864개
==> 즉, 이거시 바로 컨볼루션이 필요한 이유 !
VGGNet
16,19개의 층으로 늘어났다 ! => 깊은 신경망
3*3 kernel를 주로 사용 => 작은 필터를 사용해 더 깊은 층을 쌓음. => 복잡한 feature도 추출 가능 => 정확도 향상 !
FC layer가 3개라 파라미터가 많음
GoogLeNet
Inception blocks 사용
1. inception blocks란?
inception 이전엔 네트워크를 깊게 쌓을수록 성능은 좋아졌지만, 학습해야할 파라미터 수 또한 늘어나는 단점이 존재했다. 그래서 도입한 것이 Inception이다.

Feature Map를 효과적으로 추출하기 위해, 각각 1x1 컨볼루션, 3x3 컨볼루션, 5x5 컨볼루션, max pooling을 병렬적으로 수행하여 채널 축에서 합치는 것이다.
이런 과정을 통해 계산 비용이 줄어들면서 모델의 성능을 유지할 수 있다고 한다. but 이해 no...
우선, 1x1 컨볼루션 연산을 통해 파라미터 개수를 줄일 수 있다.

파라미터 개수를 줄이니 계산 비용도 줄 것.
ResNet
vanishing gradinet 문제를 해결 !

기존 방식은 x를 입력 받아 H(x)를 출력한다.
Residual은 출력과 입력의 차인 H(x) - x를 얻어 이를 입력에 더해주어 H(x)출력한다.
위 방식을 통해 그레디언트 소실(gradient vanishing)을 방지하는 것 .. !
제대로 와닿지 않아서 조금 찾아봤다.
<좀 더 자세히 작성>
기존 방식에서 입력받은 x가 바로 출력 H(x)을 만들어내기 때문에, H(x)와 기존 입력 x의 차이가 크다면 학습이 제대로 이루어지지 않을 수 있다.
but, 출력과 입력의 차인 H(x) - x(==입력과 출력 사이의 짧은 경로)를 입력에 더해주면서, 입력과 출력의 차이를 작게 만들며 입력 x의 정보를 보존한다.
DenseNet
ResNet와 같이 Skip Connection 기술을 사용하지만, 다른 방식으로 연결되어 있다.
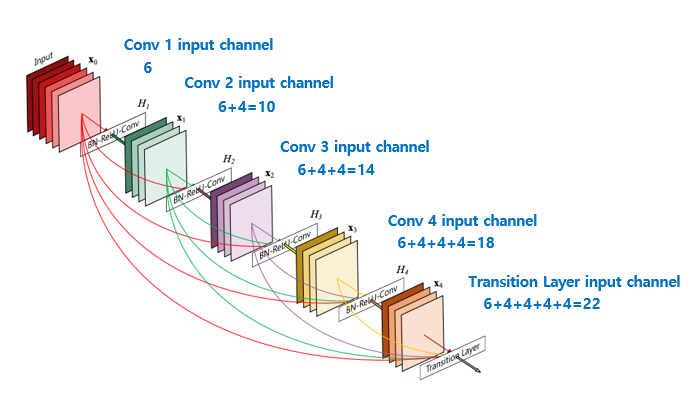
위 그림을 보면 알 수 있듯이, 모든 layer를 연결한다. ResNet과 다른 점은 concatenation을 한다는 점이다.
일반적인 CNN에서는 레이어가 깊어질수록 feature 크기가 작아져 정보 손실이 일어날 수 있는데, DenseNet는 이전 레이어의 출력값이 현재 레이어의 입력값에 concat되므로 feature가 작아지는 것을 방지하고 많은 정보를 보존할 수 있다.
'부스트캠프 > day 정리' 카테고리의 다른 글
| [week 3 - day 5] AutoEncoder & VAE 이해하기 (0) | 2023.03.23 |
|---|---|
| [week 3 - day 3] Transformer 이해하기 (0) | 2023.03.22 |
| [week 1 - day 5] cnn, rnn (0) | 2023.03.10 |
| [week 1 - day 4] 딥러닝 ~ 베이즈 통계학 (0) | 2023.03.10 |
| [week 1 - day 3] 경사하강법 (0) | 2023.03.09 |