AutoEncoder

비지도 학습의 일종이다. data와 그에 해당하는 label이 주어지지 않고, data만으로 학습시키는 방법이다.
위 그림처럼 입력이 곧 출력이다.
Encoder 부분에서 hidden layer 뉴선 수를 입력층보다 작게 하여 데이터를 압축(차원 축소)하거나, 노이즈를 추가해 원본 입력을 복원할 수 있도록 loss를 줄여나가다 보면, feature는 중요한 정보만 담게 된다.
Variational AutoEncoder (VAE)
AutoEncoder와 비슷해보이지만, 데이터의 확률 분포를 찾는다는 점에서 차이가 있다.
+) AE는 앞단(encoder)을 학습하기 위해 뒷단을 붙인거고, VAE는 뒷단(decoder)을 생성하기 위해 앞단을 붙인 것
그렇기에 완벽하게 비슷한 데이터를 만들기에는 불리할 수 있어도, 새롭고 다양한 데이터를 생성할 수 있다. =>즉, Generative model임
어떤 원리 ?
이미지 데이터가 들어오면, 그 이미지에서의 다양한 특징들이 각각의 확률 변수가 되는 어떠한 확률 분포를 만든다.
쉽게 예를 들어보자.
만약에 '웃는 사람'의 데이터가 들어왔다. 그럼 입모양, 눈의 휘어짐 등등이 feature가 되는 것이다. 이런 특징들에 대해 확률분포를 잘 학습하면, 웃는 입모양에 휘어진 눈을 토대로 새로운 이미지가 생성된다 !
뒷단을 위해 앞단을 붙였다는 것 뭔 소리?
이유는 다음과 같다 ~ !
위 과정을 통해서 왜 encoder를 붙여준 것인지 확실히 이해하였다.
어떤 수식 ?
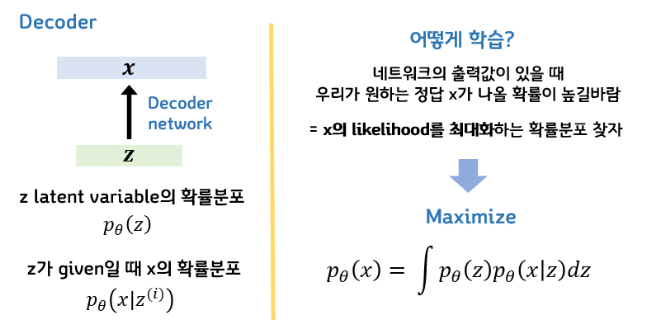
설명이 잘 되어 있어서 가져왔다. 우리는 아까 VAE가 디코더를 위해(뒷단을 생성하기 위해) 앞단을 붙인 것이라고 했다.
그러므로, Z가 있을 때, 이를 토대로 X를 만들어내고 싶은 목적에서 시작된 것.
이를 수식으로 변경하면, P(X|Z)이다. 이제, 이것을 이용해 어떻게 학습해야하는지 생각해보자.
출력 X가 있을 때, 우리가 원하는 정답 X가 최대한 많이 나오길 원함 == X의 liklihood를 최대화하는 확률분포
베이즈 정리를 이용해 수식은
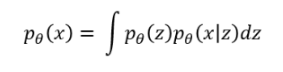
다음과 같이 표현가능하다.
(의미 : x와 z가 동시에 일어날 확률을 모든 z에 대해서 적분. 즉, x의 liklihood)
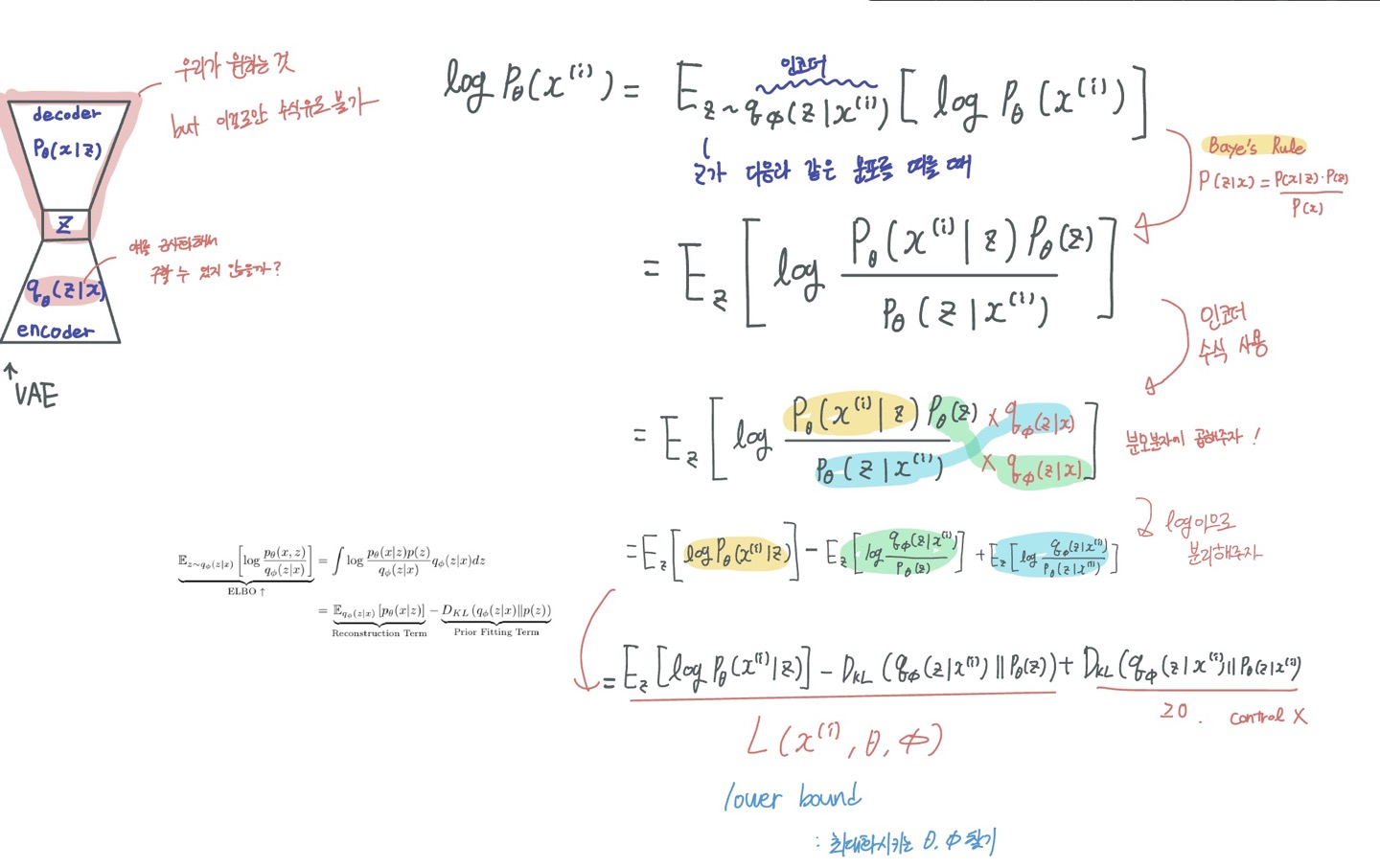
ㅎ..진짜 어렵다
참고 블로그
https://di-bigdata-study.tistory.com/4
'부스트캠프 > day 정리' 카테고리의 다른 글
| [week 8] AI 서비스 개발 기초 정리 (0) | 2023.04.26 |
|---|---|
| [week 3 - day 3] Transformer 이해하기 (0) | 2023.03.22 |
| [week 3 - day 2] CNN / modern CNN (0) | 2023.03.21 |
| [week 1 - day 5] cnn, rnn (0) | 2023.03.10 |
| [week 1 - day 4] 딥러닝 ~ 베이즈 통계학 (0) | 2023.03.10 |