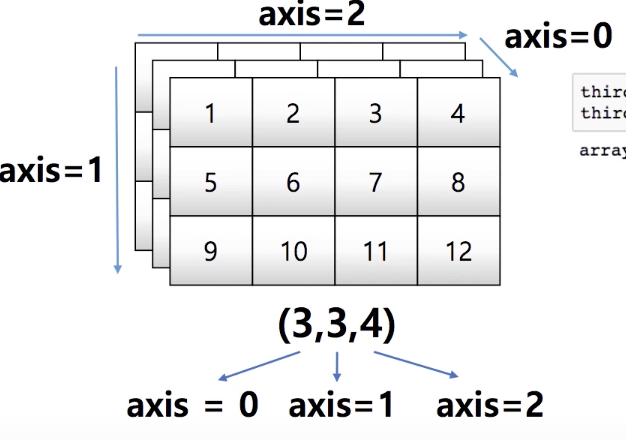
벡터란 ? 벡터는 공간에서 한 점을 나타낸다. 1차원 공간에서 (x), 2차원 공간에서 (x,y), 3차원 공간에서 (x,y,z)와 같이 한 점을 지칭한다. 위에서 언급한 (x), (x,y), (x,y,z)는 모두 원점으로부터 떨어진 거리이다. 즉, 벡터는 원점으로부터 상대적 위치를 표현한다. 애초에 x도 0+x이므로, 두 백터의 덧셈은 다른 벡터로부터의 상대적으로 이동한다고 볼 수 있다. 벡터의 노름(norm) ||x|| : 벡터의 크기(=원점으로부터의 거리)를 의미한다. 노름의 정류에 따라 기하학적 성질이 달라진다. L1-노름 : 각 성분 변화량의 절대값의 합. L2-노름 : 피타고라스의 정리를 이용한 유클리드 거리 ex) v = [1, -2, 3] L1-노름의 거리 : 1 + 2+ 3 = 6 L2-..